小白搭建Github_Pages静态网页指南
本文于2021年1月14日由AlvinCR更新
不会使用github pages的html5?这里教你简单的方法进行搭建。
以下方法适合于没有太多html编辑经验的人,无法写出一个可用于展示的网站(虽然可以展示的静态网页只需要学习三天时间就能做出来),但是如果连简单的添加位置也找不到,那就没办法了,以下方法目前(2021.1.14)只能简单添加网页,自定义css待更新。
文章导引
1 创建模板
如果有WP站点可以略过
首先从网上下载一个主题或是自己编写html5网页。解压缩到一个文件夹中,alvincr解压位置:C:\Users\Administrator\Documents\1important\alvincr.github.io
1 创建新目录
创建一个新目录用于存放新生成静态网页,我这里创建的是article,创建的目的是为了方便管理,以免根目录混乱。
2 选择文章模板
在我下载的主题中generic.html是我想要的网页类型,就以他为模板进行修改,生成未来发布文章的新模板。

3 更改模板
将模板中使用相对路径的部分改为使用绝对路径,否则将会出现以下情况:

方法:
打开模板文件,搜索href,将所有的href=”assets/css/main.css” />改为href=”../../../assets/css/main.css” />,注意这里的../的数量是你所放置的文件追溯到根目录所需的层数。例如我将新的文章放在:
网站根目录/index/manual/index-test处,因此我就需要三个../才能够回到根目录,这里根据你放的层次自己选择。
注意事项:
- 最终生成的文件名最好是index.html,为了对文章进行分类,我才创建了那么多层级的子目录。
- 一开始我认为不能使用网页地址,因为本地测试无效,但是上传到网络后发现则有效。测试地址:https://alvincr.github.io/index/manual/test-error/(一开始我测试无效才命名为error的..)
- 使用/assets/css/main.css同样在本地无效,在网站上有效。测试地址:https://alvincr.github.io/index/manual/test-error2/

2 生成网页文件
具体怎么获得这些文本,请看下文的没有站点的方法。

1 修改html代码
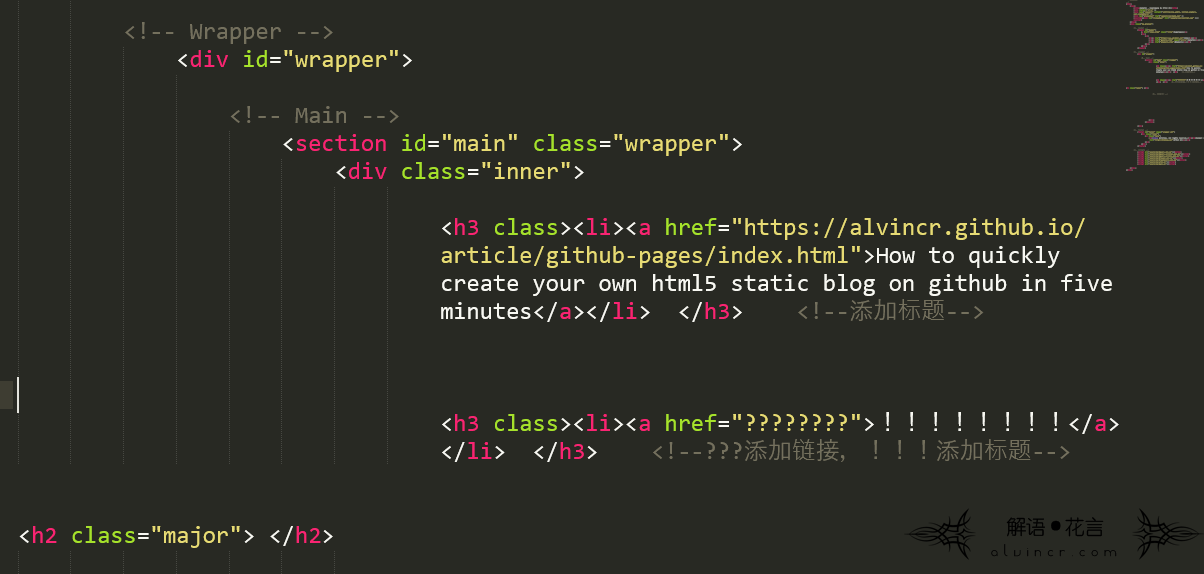
修改方法很简单,直接用记事本打开文件(我这里用的是sublime text),将里面<p>……</p>标签及中间的内容全部删除,例如删除下文选中的文本。
下图中<span class……></span>也删除,更改<h1 class=”major”>你文章的标题</h1>

简单更改一下:

2 打开效果
替换文本之后打开效果:

测试地址:https://alvincr.github.io/index/manual/test/
3 没有站点
1 Typora(通用)
Typora就不多介绍了,网上都有,界面简单功能超级强大。
注意事项
开始使用前要设置图片保存的位置,否则来自于服务器的图片,不会自动保存到本地,本地的图片保存路径是本地的路径,上传后无法打开。
选择文件-设置-图像,勾选我所勾选的内容,这样就能保存所以图片到本地了。插入图片地址也可以自定义。

不怕麻烦也可以自己手动编辑图片地址

创建文件
安装完成后,直接创建一个md文件(创建txt文件后修改为md格式)
填写内容
直接在typora写文章内容,typora支持复制文件粘贴,支持拖拽,因此写起来很方便。
例如我将:注册并使用GitHub Pages的全流程(https://alvincr.com/2021/01/github-pages/)一文翻译成英文直接复制粘贴,效果如下:

格式转换
选择视图-源代码模式(快捷键ctrl+/),就能看到文章对应的html格式
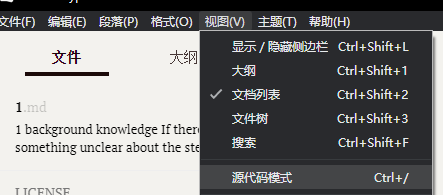
复制到模板中
将文本形式的文章内容,复制到创建好的模板中。
2 纯文字
直接使用word导出html格式即可。
然后用记事本打开输出的html文件,复制里面的代码粘贴到上文标注的地方就行了。
3 图文-富文本编译器
图文类型的文章可以用上面的typora进行,也可以安装富文本编辑器,从而利用富文本编译器直接编译网页内容。
工具
TinyMCE
CKEditor5
Medium-editor
Simditor
配置
下文使用iceEidtor进行配置
(原文打算使用Simditor配置,结果配置到一半发现simditor太不人性化了,自己给的参考demo都有问题,alvincr原来写的内容就删掉了,如果有需要可以参考:https://blog.csdn.net/gebitan505/article/details/79348846,写的很详细)
1解压缩
解压缩到github的本地仓库,也就是个人存放文件的位置。
我打算将标题和内容这两部分用富文本编辑器编译,因此需要找到html中相应的标签,使用textarea元素替换。
……
4 拥有WP站点
手动
此方法只能一篇一篇的复制,对于大量的文章还是采用插件比较快。此外这种方法添加文章,如果访客点击旁边的链接,会直接访问你的总站,并不适合所有人使用,但是我要的就是这种效果,只希望能够使用github服务器添加英文网页,最终流量引入到主站alvincr.com,因为我的站点可以根据浏览器语言自动选择显示语言。
以注册并使用GitHub Pages的全流程一文为例:https://alvincr.com/2021/01/github-pages/

在这里注意保存的格式为:仅html,个人测试使用mhtml会出现css异常,使用全部网页,会出现连接中断无法下载的情况。

选择仅html网页一定要注意,里面图片采用的链接是你服务器的链接,如果你服务器中的图片删除了,那么这个html网页中将不存在链接,因此请尽量不要删除原文章的链接和内容,添加应该不会出现问题。
以下是Dreamweaver中查看下载出的html信息:

爬取
爬取的方法太多了,python,js都行,网上教程一堆。
奇怪的方法
1 截图
写本文的时候突然想到了另一种奇怪的方法,那就是对整个网页进行全部截图(不是自己一个一个截取然后拼接,浏览器有相应的插件),然后再html中只需要添加截取的图片和链接就能做出网页..但是没有任何互动功能。
火狐功能:


2 下载器
我是用过的图片批量下载器有的就有爬取整个网站的功能,这里不推荐了,作为一种思路分享。
3 wget命令
我用过wget命令爬取整个网站,还算好用。
命令:wget https://alvincr.com/2021/01/can-not-login-in-backstage/

完整命令:wget -c -r -np -p -H -k https://alvincr.com/2021/01/can-not-login-in-backstage/ (千万别复制测试)(另:请大家学习爬取的时候,请对我的网站手下留情,服务器撑不住爬取整个网站)
wget -c -p -H -k https://alvincr.com/2021/01/can-not-login-in-backstage/
参数说明:
-c用于断点传输,对于较小的网页没必要
-r 递归下载,慎用,建议与np一起使用
-np 递归下载是不搜索上层目录
-p 下载网页所需要的所有文件(图片,js脚本,css)
-k 将绝对路径转化为相对路径,-k与-p一同使用保存到其它服务器上不会占用自己服务器的资源
提醒
完整命令:wget -c -r -np -H -k https://alvincr.com/2021/01/can-not-login-in-backstage/ (千万别复制)
后果如下:如果真的出现这种后果,建议使用mv命令将该文件夹移动到其它地方暂存,确定不需要再删除。

经过我测试发现,产生如此大量文件的原因是递归下载,并非是-p下载网页所需所有文件。使用-p参数最终只生成4个文件夹,注意这里的html文件是残留文件,代码返回报告考研看出并没有下载index.html这个文件。
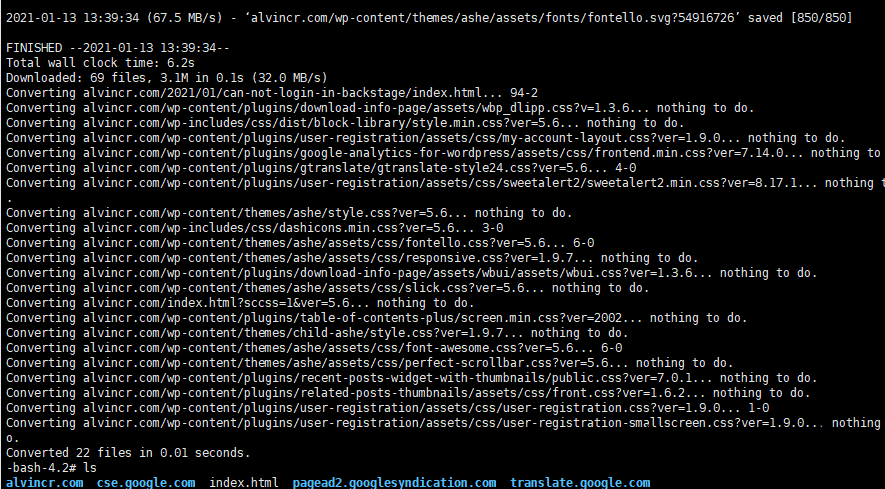
WP插件:
创建首页
我个人直接改了一下模板,下载链接看原始文章(alvincr.com)最下面。
暂时先用简陋的主页,未来再添加新效果,现效果(用的和文章一样的模板,并且没有添加什么特殊效果):

上传页面
网站优化
无法自动调整图片大小,导致图片有大有小,看起来很乱。
待更新—–
一条评论
Pingback: